I recently completed the Google Data Analytics Professional Certificate program available through Coursera. It was a big adventure covering a large swath of material I had never taken the time to look at, chief among them probably getting the hang of R. It’s a programming language I have poked at before, but never really examined in a directed way. Coming largely from a background of languages like Python and JavaScript, R is really, genuinely different.
Anyway, the course calls for the completion of a case study. Instead of using the bike dataset, I opted to look at something that has been hanging over my head for quite some time now: maternal mortality rates in the US. My initial analysis is currently being hosted on GitHub Pages and can be found here. The GitHub repo itself can be found here. As of this writing, the findings are preliminary; this project will be subject to a lot of revision, but I’m happy with this initial draft.
Why, though?
The issue of women’s health has never been spectacular in the US, but it seems to be coming to a head in recent months. The recent overturning of Roe v. Wade, declining fertility rates for sociological and economic reasons, and concerns around plastics having pronounced physiological effects are on many people’s minds. Additionally, I know people for whom this is a personal concern.
What did you find?
It’s still a preliminary analysis subject to expansion and review, but it looks like one big culprit in the drastic increase in maternal mortality rates in the US is increasing maternal age. I don’t mean women in their 40s and 50s who are having unsafe geriatric pregnancies; the average age for women dying of maternal mortality conditions is still entirely under 36. In fact, of particular interest was that changes in maternal mortality rates has cleaved around 40 in recent years, with cases being on the decline in women in those much older cohorts.
Everything after that was beyond the scope of my analysis. There could be any number of reasons why maternal ages are increasing. I posited that a general lack of trust in the economy following the Great Recession of 2008 could be one reason, but climate change, labor situations, and the general cultural disposition to families could also be factors.
Also, while discussing the project with a friend, we got the idea of comparing maternal mortality to mining. After using R to run some statistics from MSHA, we found out about this:
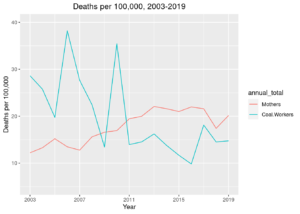
Yeah. Fatalities for people working in the coal mining industry were lower per 100,000 than those for mothers. In my mind, there’s something somber and concerning about looking at the cultural touchstone of dirty and dangerous work, comparing it to something that is quintessentially human, and being surprised at which one is more dangerous. Very generously, this could be characterized as a victory for improvements in safety standards and the continued application of engineering to the well-understood problems of mining, but given the sharp increase in maternal mortality in the US in particular, I’m personally having a hard time conceptualizing it that way.
What’s next?
Broadly, taking this course and doing this case study has given me a new lens on learning programming languages. Early in the process of learning R, my brain constantly thought of how it would solve problems with Python, tools that I am much more familiar with. R felt kludgy, cumbersome, and unnatural, right up until it didn’t. At some point, R became the natural tool for the job of data analysis, and I started solving problems in a way that I know would be difficult if I were to do the same in Python. From now on, I aspire to learn tools such that they are obviously the perfect fit for their respective jobs.
Less abstractly, I will be doing more projects with R. It allows for a certain fluidity in exploring data that I’m gaining a deep appreciation for, and I’m very curious to see how involved the ecosystem is. For instance, while working on the maternal mortality case study, I took the liberty of learning just a bit about geographic information systems. Within a day, I got the hang of calling the USGS API and applying its data to an interactive map, a project which I will be posting about very shortly. Early Days!